Designing Data Feeds & APIs for Programmatic Pages on Lovable Sites (Best Practices)
A guide covering designing Data Feeds & APIs for Programmatic Pages on Lovable Sites (Best Practices).

TL;DR
- Programmatic pages fail when feeds lack stable IDs, geo tokens, and clear schema mapping — fix feeds first.
- Quick answer: deliver a structured, versioned feed (CSV/JSON) with canonical IDs, explicit geo fields, timestamps, and mapped template tokens to publish reliable api-driven programmatic pages.
- Always include a canonical, stable ID and local geo tokens in every feed row — it powers consistent entity signals for AI and local search.
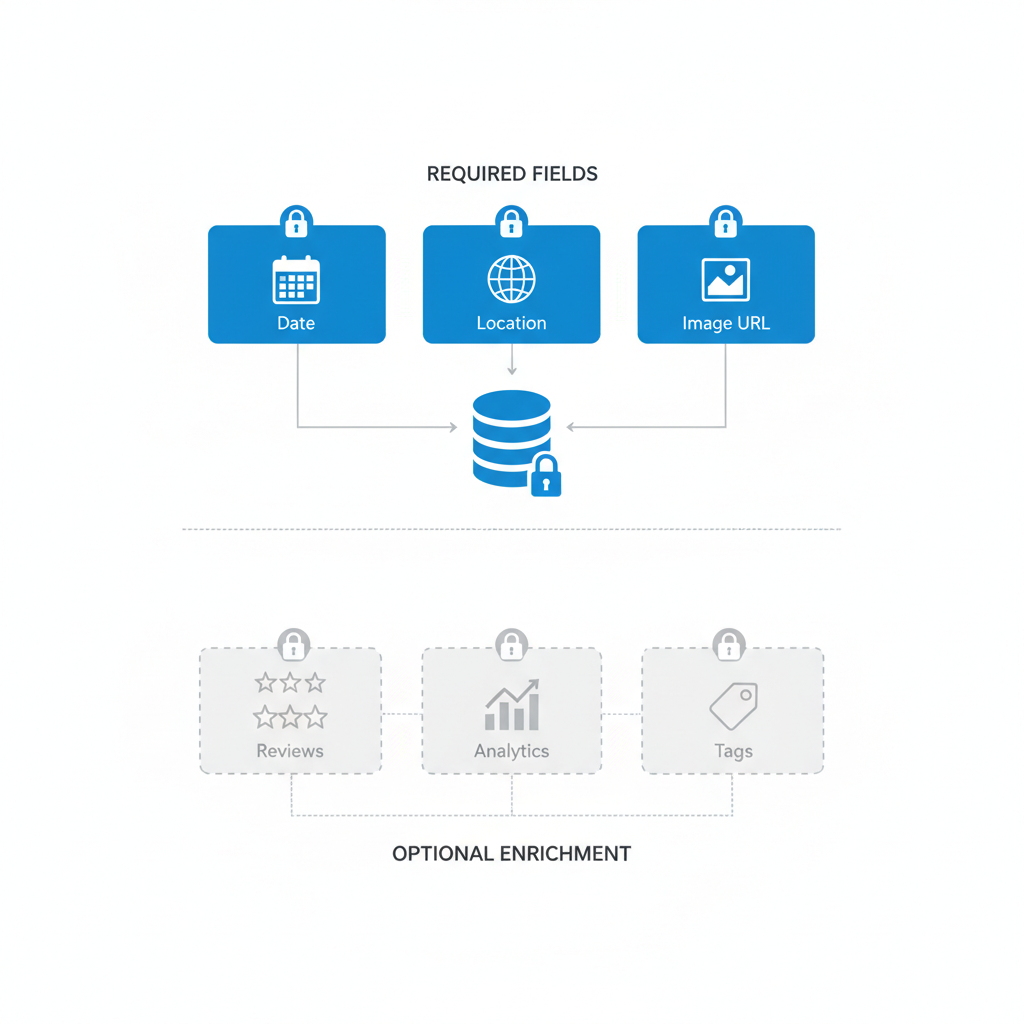
Why structured data feeds matter for programmatic SEO
If your programmatic pages are inconsistent, thin, or vanish from search results overnight, the root cause is often the feed. Programmatic data feeds lovable sites depend on must be predictable, complete, and mapped to the publishing templates. Without structure, templates render poor titles and duplicate content, indexers fail to assign authority, and local search signals get lost.
Programmatic pages on Lovable sites are successful when data rows are treated like canonical entities: unique and stable across updates. A single malformed price field or missing geo token can produce thousands of low-quality pages in one publish. The solution is a feed-first approach: validate and enrich data upstream, map fields to template tokens, and publish via reliable API-driven programmatic pages that support incremental updates and idempotency.
Practical example: an online directory publishes 50,000 city-level pages from a product inventory feed. If city tokens are missing for 20% of rows, those pages either produce global-level content or duplicate other pages, which dilutes signals. Fixing the feed to include city, region, and lat/lon reduces indexation errors and improves local visibility.
Always include a canonical, stable ID and local geo tokens in every feed row — it powers consistent entity signals for AI and local search.
This section explains why structured feeds matter and what you gain by doing them right: consistent titles, predictable canonicals, accurate sitemaps, and reliable schema.org markup for AI-answer surfaces. The rest of this guide shows how to design required fields, enrichment options, API patterns, and governance so your lovable site programmatic templates feed produces pages that search engines and AI answer boxes trust.
Who this is NOT for
This guide is not for teams with single static landing pages or sites that never update content programmatically. It’s also not for projects where content can’t be modeled as discrete rows with stable IDs (for example, purely user-generated free-text streams). If you lack engineering resources to implement API-driven programmatic pages, adopt a phased approach: start with a limited feed and a staging environment before full rollout.
Feed schema: required fields vs optional enrichment
Why separate required from optional? Required fields ensure a page renders correctly and is unique in search. Optional enrichment raises quality and supports schema.org tokens for AI-answer surfaces. Design your feed schema with minimal required fields plus a structured enrichment layer that can be added over time.
Minimum required fields (example for a product/place page): unique_id, title, description, canonical_url, last_updated. These must be present for every row. Optional enrichment includes geo fields, pricing, availability, categories, tags, images, FAQs, and review aggregates. Treat optional fields as quality signals: pages with more enrichment should be prioritized for indexing and internal linking.
Step-by-step approach to define your schema:
- Audit the template tokens your lovable site programmatic templates feed consumes.
- Identify the smallest set of fields needed to render a valid, unique page.
- Mark all additional fields as enrichment and create validation rules that mark rows as 'low', 'medium', or 'high' quality.
- Design ingest pipelines that can attach enrichment asynchronously (images and reviews can arrive later without breaking the canonical page).
Include quality thresholds: for instance, require title length between 20–70 characters, description between 100–320 characters, and at least one image URL for high-quality pages. For AI-answer readiness, map structured fields to schema.org types (see mapping table later).
Identifier, title, description, canonical URL
Identifier: use a stable, opaque ID like an internal UUID or a deterministic hashed key. Avoid composite keys that change when any attribute changes. The identifier becomes the single source of truth for deduplication, incremental updates, and canonical resolution.
Title: the title token must be human-readable and template-safe. Provide a canonical_title field and a title_template variable only if you control templating changes. Include variants when available: title_localized or title_short.
Description: prefer a rich description field (100–320 characters) suitable for meta description and on-page intro. If you supply both short_description and long_description, map them explicitly.
Canonical URL: either supply the final canonical or a slug token that follows deterministic rules. If your feed includes canonical_url, the platform should respect it; otherwise generate the canonical from stable_id and slug. Make canonical decisions upstream to avoid content duplication across similar entities.
Geo fields, pricing, availability, categories, images
Geo fields: explicitly supply city, region, country, latitude, and longitude. For local answers and AI extraction, lat/lon are often decisive. Use standardized region codes (ISO where possible) and avoid free-text region names only. Example tokens: city, region_code, country_code, lat, lon.
Pricing & availability: price_currency and price_value should be separate. For availability, use a finite set (in_stock, out_of_stock, pre_order). If you list dynamic pricing, include price_last_updated and price_effective_date to support time-bound indexing.
Categories: supply both category_id (stable) and category_label (human-readable). This supports taxonomy consistency across templates and faceted search. Images: at least one image_url is required for high-quality pages; also provide image_width and image_height if available. For structured feeds for programmatic seo, images and categories are common enrichment fields that increase click-through rates and AI trust signals.
API design patterns for reliable publishing
APIs are the publishing mechanism between your data layer and the lovable site platform. Choose patterns that reduce full-publish blast radius and support selective re-publishing. The core patterns: bulk upload (batch), incremental update (delta), and upsert-by-id (idempotent). These patterns apply whether you push CSV, JSON, or stream events.
Bulk uploads are useful for initial imports but risky for daily operations at scale. Use them for onboarding, not for routine syncs. For day-to-day publishing, adopt incremental updates and an upsert endpoint keyed by stable_id. Upsert-by-id guarantees idempotency: repeated calls with the same payload produce the same state.
Design your API to accept a manifest describing the feed (file type, schema version, record count, timestamp) and return a synchronous validation summary. If validation fails, the API should reject the entire batch only when required fields are missing. Otherwise accept partial rows with explicit row-level statuses to allow automated enrichment pipelines to fix issues without blocking all rows.
Example API behavior rules:
- Return a 200 with a processing_id for accepted feeds and provide a validation report endpoint.
- Support PATCH/PUT/DELETE by stable_id so callers can reconcile their source-of-truth.
- Expose a feed schema endpoint that returns required fields, types, and enumerations so clients can validate before upload.
Design APIs to be idempotent and to report row-level validation status — that makes rollbacks and automated remediation straightforward.
For api-driven programmatic pages, include hooks for previewing a rendered template using a sample row. Provide a preview endpoint that returns the final HTML or rendered tokens so content owners can catch tokenization errors before publish.
Incremental updates, change-detection, and idempotency
Incremental updates reduce load and risk. Send only changed rows with a last_modified timestamp. On the platform side, implement change-detection using the stable_id and last_modified; reject older timestamps to prevent accidental rollbacks. Idempotency keys at the API layer prevent duplicate processing during retries.
Concrete thresholds and rules: require P95 processing latency under 300ms per API call for single-item upserts in staging; for batch ingest, aim for throughput of at least 1,000 rows per minute for medium-size sites. If you cannot meet those numbers, queue ingestion and process asynchronously while exposing progress to the caller.
Example: a retailer updates prices hourly. Your feed should include price_last_updated and the API should accept an hourly delta containing only items that changed. The platform applies the delta, marks affected pages as updated in sitemaps, and triggers reindexing for high-priority entities.
Rate limiting and throttling when publishing to Lovable platforms
Protect the platform and your integration by respecting rate limits. The typical pattern: soft limit with informative headers (X-RateLimit-Remaining) and hard limit that returns 429 with Retry-After. Implement exponential backoff in clients and support bulk endpoints to mitigate 429 storms.
Example policy (conditional): if your platform supports throttling, adopt a default of 500 upserts per minute for production clients and a lower rate for anonymous or trial accounts. Where true numbers are unknown, implement client-side batching: group upserts into 50–200 row batches depending on payload size.
Publishers should also provide scheduling options: low-priority feeds can be processed during off-peak windows. Always include webhooks or callback URLs to notify clients when processing completes so clients can avoid polling aggressively.
Expose validation and processing results, not just success codes — actionable feedback prevents repeated publish failures.
Data hygiene and quality checks
Data hygiene prevents bulk publishing from creating low-quality pages. Run validation at three gates: pre-ingest (client-side), ingest-time (API validation), and pre-publish (render-time checks). Each gate should enforce required fields and flag enrichment issues without blocking graceful publishing when appropriate.
Create automated quality tiers. For example:
- Tier A — high quality: all required fields + images + pricing + geo. Eligible for immediate sitemap inclusion.
- Tier B — acceptable: required fields present, some enrichment missing. Eligible for limited indexing and internal linking.
- Tier C — low quality: missing required enrichment or failing validation. Publish in staging only until fixed.
Automated checks should include schema validation, length checks, allowed value lists, image accessibility, and duplicate detection. Run a content quality score that sums weighted features (title quality, description length, image presence, category match). Use that score to decide whether to flag the row for manual review or to publish with limited exposure.
Deduplication strategies and uniqueness rules
Deduplication requires clear rules. Use stable_id as the primary uniqueness key. For entities that might map to the same final URL (for example, multiple SKUs per product page), define a canonical resolution rule upstream and include canonical_id in the feed so the platform can merge gracefully.
Detect duplicates using a combination of stable_id, normalized titles, and key attributes (city + name + category). For fuzzy matches, apply a thresholded similarity check (for example, normalized Levenshtein < 0.15) and surface matches for human review rather than automatically merging when similarity is ambiguous.
Validating structured-data tokens and schema compliance
Schema compliance matters for AI-answer surfaces and rich snippets. Validate tokens against schema.org types where applicable (Product, Place, LocalBusiness, Event). Provide a validation endpoint that translates feed fields into a previewed JSON-LD block so teams can verify markup before publish.
Include automated checks for common schema problems: missing @context, incorrect priceCurrency format, missing geo coordinates where Place is detected. For structured feeds for programmatic seo, ensure you produce JSON-LD that matches the page content; mismatched schema invites penalties or ignored markup.
Connecting feeds to LovableSEO templates and sitemaps
Mapping feeds to templates is the moment your data becomes a page. For lovable site programmatic templates feed integrations, design a mapping layer that converts feed tokens into template tokens and controls which pages appear in sitemaps. Use a two-step publish: staging-render + sitemap inclusion so you can gate indexation by quality tiers.
Practical steps:
- Export a canonical sample row for each template and run a full render to check token substitution.
- Create a mapping manifest that lists feed_field → template_token → schema.org property.
- Generate a sitemap only for rows marked Tier A or Tier B based on your quality scoring rules.
For data feed best practices seoagent users: configure your sitemap generator to only include URLs where last_updated is recent and quality_score exceeds your threshold. This reduces crawl waste and improves the chance for AI extractor trust.
Mapping feed fields to template tokens
Build a field mapping file (YAML/JSON) that is the single source of truth for token mapping. That file should include: feed_field, required_flag, fallback_value, token_name, and schema_annotation. Keep mapping under version control so template changes are auditable.
Example mapping entry:
{ "feed_field": "city", "required": true, "fallback": "", "token": "{{city}}", "schema": "addressLocality"
}
When the template expects {{price}} but the feed supplies price_value and price_currency, mapping must combine them or the renderer should apply a format function. Define formatting rules in the mapping manifest to avoid ad-hoc template logic.
Handling missing fields and fallback content
Never leave tokens empty. Provide deterministic fallbacks: if image_url is missing, use a category-level image; if city is missing, do not generate a city-specific title — instead render a different template that is not geo-specific. Avoid templated fallbacks like "Service in [city]" when city is empty; instead switch to a neutral header.
Fallback rules examples:
- If description missing, use long_description or assemble one from key attributes: "[name] in [city] — [category]".
- If price missing, show "price on request" and set a low-quality flag so these pages are deprioritized for sitemaps.
Monitoring, error handling, and automated rollbacks
Monitor publishing pipelines end-to-end: feed ingestion, validation, render, sitemap generation, and search index signals. Instrument metrics: rows_processed, validation_fail_rate, publish_error_rate, average_render_latency, and sitemap_inclusion_count. Set alert thresholds and automated rollback triggers (for example, if publish_error_rate > 5% in a 10-minute window, pause processing and roll back the last batch).
Error handling should include granular status codes and human-readable messages. For automated rollback, record a snapshot of the pre-publish state and use it to restore either the previous feed or previous canonical page rendering. Rollbacks should be reversible and logged with a causal reason and a responsible user or system id.
Monitoring must also detect stale content. Track last_updated per page and alert when high-priority pages exceed your freshness SLA (for example, more than 30 days without an update for inventory-driven content). Regularly surface stale content reports so content teams can prioritize refreshes.
Alerts for publishing failures and stale content
Configure alerts for critical failures: validation regressions, high duplicate rates, unexpected drops in sitemap inclusion, and spikes in 5xx publishing errors. Use escalation rules: page-level alerts go to engineers, quality-score regressions go to content owners, and SLA breaches escalate to product leadership.
Alerting examples and thresholds (example only):
- Validation failure rate > 3% in 15 minutes: immediate alert to integration team.
- Sitemap inclusion drops by >10% week-over-week: notify SEO and product.
- Average render latency P95 > 500ms: performance alert to infra team.
Example feed payloads (CSV, JSON) and sample API request
Include concrete payload examples so engineers can copy and adapt. Below is a JSON fragment demonstrating geo tokens and stable IDs that power local search and AI answers:
{ "stable_id": "uuid-1234-abcd", "title": "Bluebird Cafe — Acoustic music venue", "description": "Intimate music venue in downtown, weekly open-mic nights.", "canonical_url": "https://example.com/venues/bluebird-cafe", "city": "Nashville", "region_code": "TN", "country_code": "US", "lat": 36.1627, "lon": -86.7816, "price_min": 10, "price_currency": "USD", "image_url": "https://cdn.example.com/images/bluebird.jpg", "last_updated": "2026-02-15T08:12:00Z"
}
CSV example (header row):
stable_id,title,description,canonical_url,city,region_code,country_code,lat,lon,price_min,price_currency,image_url,last_updated
uuid-1234-abcd,"Bluebird Cafe","Intimate music venue","https://example.com/venues/bluebird-cafe","Nashville","TN","US",36.1627,-86.7816,10,USD,"https://cdn.example.com/images/bluebird.jpg","2026-02-15T08:12:00Z"
Sample API request (conceptual): POST /api/feeds with multipart upload, returning a processing_id. The server then exposes GET /api/feeds/{processing_id}/report for validation details. This pattern keeps clients informed without blocking on long ingest operations.
Governance: versioning feeds and testing environments
Version feeds and mapping manifests. Include a schema_version field in feed headers and require backward-compatible changes where possible. Keep a staging environment that mirrors production behavior so teams can run full renders and sitemap generation without affecting live indexation.
Governance checklist (copyable):
| Governance Item | Requirement |
|---|---|
| Schema versioning | Include schema_version header in every feed and mapping manifest under version control |
| Staging rendering | Require a preview render for new templates and mapping changes |
| Rollback plan | Maintain snapshots of previous publishes for 30 days |
| Access control | Restrict feed upload and mapping edits to approved roles |
Test environments should include synthetic feeds to simulate edge cases (missing geo, duplicate rows, large image sizes). Run nightly smoke tests: render a representative 100-row sample and validate schema output. Treat passing smoke tests as a gating condition for automated daily publishes.
Conclusion — implementation checklist for engineering + SEO
Implementing reliable programmatic pages requires feed-first discipline, API patterns that support idempotency, and governance that prevents low-quality pages from reaching indexers. Use the checklist below to align engineering and SEO teams before the first full publish.
| Task | Owner | Done? |
|---|---|---|
| Define minimal required feed schema (stable_id, title, description, canonical_url, last_updated) | Engineering + SEO | [ ] |
| Add geo tokens (city, region_code, country_code, lat, lon) to feed | Data | [ ] |
| Implement upsert-by-id API with row-level validation | Engineering | [ ] |
| Build mapping manifest and preview render endpoint | Engineering | [ ] |
| Create quality tiers and sitemap gating rules | SEO | [ ] |
| Set up staging environment and rollback snapshots | Platform Ops | [ ] |
FAQ
What is designing data feeds & apis for programmatic pages on lovable sites (best practices)? Designing data feeds & apis for programmatic pages on lovable sites is the practice of creating well-structured, versioned feeds and idempotent APIs that map stable feed tokens to template tokens, include explicit geo fields and enrichment, validate schema compliance, and gate sitemap inclusion to produce reliable, indexable programmatic pages.
How does designing data feeds & apis for programmatic pages on lovable sites (best practices) work? It works by treating each feed row as a canonical entity with a stable identifier, validating required fields at ingest, applying enrichment and deduplication rules, mapping fields to LovableSEO-compatible templates, and publishing via APIs that support incremental updates, monitoring, and rollback.
Ready to Rank Your Lovable App?
This article was automatically published using LovableSEO. Get your Lovable website ranking on Google with AI-powered SEO content.
Get Started